Author: John Eckersberg
Source: Planet OpenStack
Most people probably don’t give too much thought to our old friend,
TCP. For the most part, it’s just a transparent piece of
infrastructure that sits between clients and servers, and we focus
most of our time paying attention to the endpoints, and rightly so.
Almost always it does the right thing, and we don’t care. Life is
good.
However, sometimes you do need to care. This is about one of those
times.
Background
This is what a typical HA deployment of Red Hat Enterprise Linux
OpenStack Platform looks like, focusing specifically on the RabbitMQ
service:
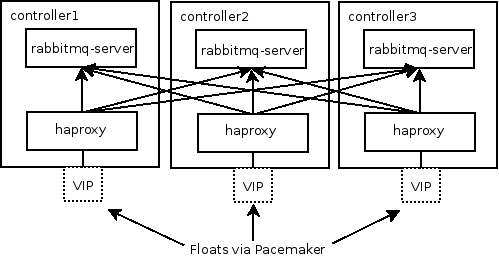
There are three controller nodes that are part of a pacemaker cluster.
There is a virtual IP (VIP) for AMQP traffic that floats between the
three controllers and is controlled by pacemaker. HAProxy is bound to
listen on the VIP on all three controller nodes. At any point in
time, only one controller will have the VIP, and only this node will
be responsible for directing AMQP to the backend RabbitMQ servers via
HAProxy. This HAProxy instance balances the traffic across all three
instances of rabbitmq-server, one on each controller.
VIP Failover
At this point, everything is happily chugging along. There’s a bunch
of clients (or in AMQP parlance, consumers and producers) connected
through the VIP, through HAProxy, ultimately to RabbitMQ on the
backend. What happens if the VIP fails over to another node?
For the clients, it’s pretty straightforward. The client will try to
write to the server on the existing connection. (This is either a
“normal” write, or via a TCP keepalive probe, which is a related topic
that I won’t go over here. Just assume it’s there). Since the packet
gets routed to a new host (whichever one newly picked up the VIP), and
the existing TCP session is not recognized by the new host, the client
will receive a TCP RST. The client cleans up the connection and
reconnects to the VIP to establish a valid session on the new server.
However, the server behavior is more interesting. Consider:
-
There’s a connection, through the VIP, through HAProxy, to
RabbitMQ -
The VIP fails over
-
RabbitMQ writes data to the connection. HAProxy receives the
data from RabbitMQ and writes the data back to the client.
What happens?
The source address for the connection from HAProxy back to the client
is the VIP address. However the VIP address is no longer present on
the host. This means that the network (IP) layer deems the packet
unroutable, and informs the transport (TCP) layer. TCP, however, is a
reliable transport. It knows how to handle transient errors and will
retry. And so it does.
TCP Retries
TCP generally holds on to hope for a long time. A ballpark estimate
is somewhere on the order of tens of minutes (30 minutes is commonly
referenced). During this time it will keep probing and trying to
deliver the data.
See RFC1122, section 4.2.3.5 for
details on the specification and the linux documentation
for the related tunables in the kernel.
It’s important to note that HAProxy has no idea that any of this is
happening. As far as its process is concerned, it called write() with
the data and the kernel returned success.
Work Queues / RPC
Let’s take a step back now and consider what impact this has to the
users of messaging. RPC calls over AMQP are a common use case. What
happens (simplified) is:
-
The RPC client sends the request message into a work queue.
-
RabbitMQ delivers the message to one of the workers consuming
messages from the work queue. How this gets scheduled is
configuration-dependent. -
The worker does the work to service the request and sends the
reply back to the client.
If the VIP has failed over, #2 can trigger the problematic behavior
described above. RabbitMQ tries to write the RPC request to one of
the workers that was connected through the VIP on the old host. This
request gets stuck in TCP retries. The end result is that the client
never gets its answer for the request and throws an error somewhere.
The problem is that the TCP retries behavior allows “dead” consumers
to hang around in RabbitMQ’s view. It has no idea that they’re dead,
so it will continue to send messages until the consumer
disconnects—when the TCP retries gives up some tens of minutes
later.
TCP_USER_TIMEOUT
Since Linux 2.6.37, TCP sockets have an option called
TCP_USER_TIMEOUT. Here’s the original commit message, since it
describes it better than I could:
commit dca43c75e7e545694a9dd6288553f55c53e2a3a3
Author: Jerry Chu <hkchu@google.com>
Date: Fri Aug 27 19:13:28 2010 +0000
tcp: Add TCP_USER_TIMEOUT socket option.
This patch provides a "user timeout" support as described in RFC793. The
socket option is also needed for the the local half of RFC5482 "TCP User
Timeout Option".
TCP_USER_TIMEOUT is a TCP level socket option that takes an unsigned int,
when > 0, to specify the maximum amount of time in ms that transmitted
data may remain unacknowledged before TCP will forcefully close the
corresponding connection and return ETIMEDOUT to the application. If
0 is given, TCP will continue to use the system default.
Increasing the user timeouts allows a TCP connection to survive extended
periods without end-to-end connectivity. Decreasing the user timeouts
allows applications to "fail fast" if so desired. Otherwise it may take
upto 20 minutes with the current system defaults in a normal WAN
environment.
The socket option can be made during any state of a TCP connection, but
is only effective during the synchronized states of a connection
(ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2, CLOSE-WAIT, CLOSING, or LAST-ACK).
Moreover, when used with the TCP keepalive (SO_KEEPALIVE) option,
TCP_USER_TIMEOUT will overtake keepalive to determine when to close a
connection due to keepalive failure.
The option does not change in anyway when TCP retransmits a packet, nor
when a keepalive probe will be sent.
This option, like many others, will be inherited by an acceptor from its
listener.
Signed-off-by: H.K. Jerry Chu <hkchu@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This is exactly what we want. If HAProxy writes something back to the
client and it gets stuck retrying, we want the kernel to timeout the
connection and notify HAProxy as soon as possible.
Fixing HAProxy
I talked to Willy Tarreau over at HAProxy about this behavior, and he
came up with this
patch
which adds a new tcp-ut option, allowing the user to configure the
TCP_USER_TIMEOUT value per listening socket. This is available in the
1.6 development branch of HAProxy, and is currently being backported
to Fedora and RHEL OpenStack Platform.
Fixing Linux
I told you a little white lie before. Although Linux gained
TCP_USER_TIMEOUT in 2.6.37, it was broken for some cases until 3.18.
Importantly, one of those cases is the case I’ve discussed here. It
doesn’t handle the situation where the TCP layer has put packets into
the output queue, but the packets weren’t transmitted. That’s the
case when IP can’t route it. So you’ll need either a kernel >= 3.18,
or one which has this patch backported and applied:
commit b248230c34970a6c1c17c591d63b464e8d2cfc33
Author: Yuchung Cheng <ycheng@google.com>
Date: Mon Sep 29 13:20:38 2014 -0700
tcp: abort orphan sockets stalling on zero window probes
Currently we have two different policies for orphan sockets
that repeatedly stall on zero window ACKs. If a socket gets
a zero window ACK when it is transmitting data, the RTO is
used to probe the window. The socket is aborted after roughly
tcp_orphan_retries() retries (as in tcp_write_timeout()).
But if the socket was idle when it received the zero window ACK,
and later wants to send more data, we use the probe timer to
probe the window. If the receiver always returns zero window ACKs,
icsk_probes keeps getting reset in tcp_ack() and the orphan socket
can stall forever until the system reaches the orphan limit (as
commented in tcp_probe_timer()). This opens up a simple attack
to create lots of hanging orphan sockets to burn the memory
and the CPU, as demonstrated in the recent netdev post "TCP
connection will hang in FIN_WAIT1 after closing if zero window is
advertised." http://www.spinics.net/lists/netdev/msg296539.html
This patch follows the design in RTO-based probe: we abort an orphan
socket stalling on zero window when the probe timer reaches both
the maximum backoff and the maximum RTO. For example, an 100ms RTT
connection will timeout after roughly 153 seconds (0.3 + 0.6 +
.... + 76.8) if the receiver keeps the window shut. If the orphan
socket passes this check, but the system already has too many orphans
(as in tcp_out_of_resources()), we still abort it but we'll also
send an RST packet as the connection may still be active.
In addition, we change TCP_USER_TIMEOUT to cover (life or dead)
sockets stalled on zero-window probes. This changes the semantics
of TCP_USER_TIMEOUT slightly because it previously only applies
when the socket has pending transmission.
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Reported-by: Andrey Dmitrov <andrey.dmitrov@oktetlabs.ru>
Signed-off-by: David S. Miller <davem@davemloft.net>
I’ve proposed this for RHEL 7.
The (Hopefully Very Near) Future
Most of this behavior can be detected and avoided by using application
layer AMQP heartbeats. However at this time the feature is not
available in oslo.messaging, although this
review has been close for a
while now. Even with heartbeats, having TCP timeouts as another knob
to tweak is a good thing, and it has more general applicability. I’ve
had success using the timeouts to better detect inter-cluster failures
of RabbitMQ nodes as well, but that will be a future post.
Powered by WPeMatico