Author: Sahdev Zala
Source: Planet OpenStack
I have been asked many times to help understand specific TOSCA topics by novice or intermediate TOSCA users. As one can expect, the OASIS TOSCA specification covers all the topics in great detail but in many cases, for the sake of brevity, the specification is required to limit its scope of examples that may help to clarify certain topics. In a planned series of few blog posts I would like to cover what I feel are some of the most important TOSCA topics with a hope that they will serve as a good and concise reference of a specific task for TOSCA users. All posts in the series will keep TOSCA Simple Profile in YAML version 1.0 specification in mind. In this first post in the series I will cover TOSCA Cloud Service Archive or what it is commonly known as TOSCA CSAR. I will describe TOSCA CSAR structure with an N-Tier ELK stack example. I will also describe how OpenStack TOSCA-Parser and Heat-Translator supports CSAR usage.
The TOSCA CSAR is not new as it was first created with the TOSCA XML specification a few years back. However, with the latest TOSCA YAML specification the CSAR has been simplified both in terms of overall CSAR file structure as well as meta-file content. The original CSAR specification for TOSCA XML is available at the OASIS TOSCA website.
So what is TOSCA CSAR and why would I care about it?
The CSAR is a container file. Besides the TOSCA service template of a cloud application it includes all artifacts required to manage the life cycle of the corresponding cloud application (i.e. the implementation artifacts of the operations of the node types) as well as all artifacts to execute the cloud application (i.e. the deployment artifacts of the node types like virtual images etc.). In order to execute and manage the life cycle of a cloud application in certain environments all corresponding artifacts must be available in that environment. This means that beside the definition of the cloud application workload, the deployment artifacts and implementation artifacts must be available in that environment. This is a typical use case and that is why the TOSCA specification defines CSAR.
To provide a better understanding of the CSAR structure, I am using the TOSCA CSAR N-Tier ELK example that I have created working with the TOSCA-Parser development team and the TOSCA Technical Committee (TC). The CSAR provides a TOSCA service template in YAML, that defines the application workload and various nested templates, as well as artifacts that are needed to deploy a Node.js sample application on a Node.js server which uses a MongoDB database server for database management and is monitored by using the ELK. There are a total five servers created with deployment, one for each Node.js, MongoDB, Elasticsearch, Logstash and Kibana. The Node.js server is the one where the sample pizza store application from PayPal is deployed along with rsyslog and collectd for collecting the logs. Figure 1 provides a high level overview of the TOSCA ELK stack. The complete CSAR is available here. It is also available at the OASIS TOSCA. The TOSCA-Parser and Heat-Translator supports TOSCA CSAR with .zip and .csar extension.
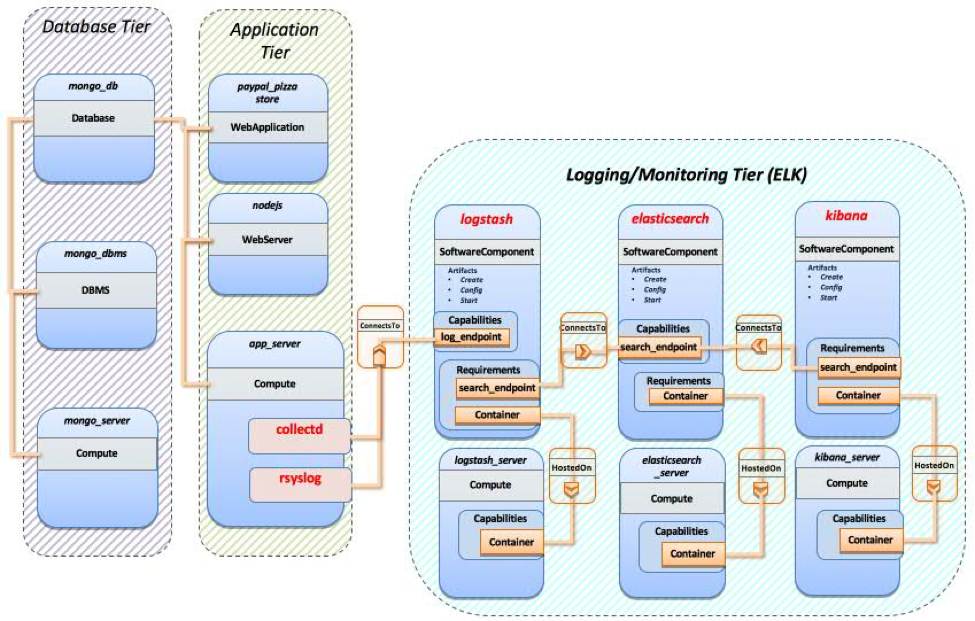
Figure 1. High level view of ELK stack modeled with TOSCA
Alright, let’s talk about CSAR structure. A CSAR must contain a sub-directory called TOSCA-Metadata which in turn requires to have TOSCA.meta file. The TOSCA.meta metadata file is what provides entry information for a TOSCA Parser or TOSCA orchestrator processing the CSAR file.
Figure 2 below shows a meta file used in the TOSCA ELK CSAR.

Figure 2. Content of TOSCA.meta file
As you can see, the content of the meta file is very simple. The Entry-Definitions provides information of the main service template file which is a tosca_elk.yaml file located in the Definitions folder in the case of the TOSCA ELK CSAR. It is worth noticing that in the original TOSCA CSAR created for XML specification, a directory named Definitions was required and it must contain a TOSCA main service template definition file but as part of the simplification made during the TOSCA YAML profile work the CSAR is not required to have such a specific Definitions directory.
The CSAR file may contain other directories with arbitrary names and contents. The names can be arbitrary but it is recommended to provide meaningful names for easier usage and reusability. Figure 3 provides the overall structure for the TOSCA ELK CSAR. As you can see the CSAR has a Definitions folder, which contains the main service template, and all other YAML files needed for the deployment. All the Python specific modules are under the Python folder, where as the Scripts directory contains other artifacts. An optional README file is also provided. The main service template file, tosca_elk.yaml in this case, is responsible to provide pointers to the nested templates and artifacts that it refers to.
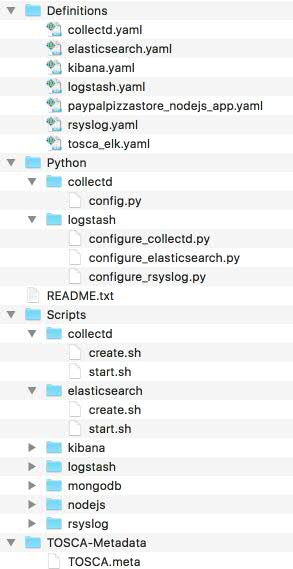
Figure 3. TOSCA CSAR file structure
The TOSCA-Parser and Heat-Translator tools allow TOSCA YAML template files or CSAR as an input to parse and translate to the Heat Orchestration Template (HOT), and optionally automatically deploy translated content into an OpenStack cloud. For TOSCA NFV specific support in the TOSCA Parser, refer to my blog on OpenStack TOSCA Parser for Network Functions Virtualization (NFV). In order to parse, translate and deploy the CSAR into an OpenStack cloud, follow these steps:
- Install the TOSCA Parser – run
sudo pip install tosca-parserto install the latest release or you can get the latest code from the TOSCA-Parser github repository and install it manually. - Install the Heat Translator – run
sudo pip install heat-translatorto install the latest release or you can get the latest code from the Heat-Translator github repository and install it manually. - Download the csar_elk.zip or csar_hello_world.zip
A TOSCA CSAR can now be parsed with TOSCA-Parser using the Command Line Interface (CLI). An example command is:
tosca-parser --template-file=csar_elk.zip
or if you are using the Heat-Translator, you could translate it to HOT by simply using the following command. As you can expect, before the translation, the Heat-Translator first validates the CSAR using TOSCA-Parser programmatically.
heat-translator --template-file=csar_elk.zip
The Heat-Translator can be used to automatically deploy translated content by providing –deploy option on the CLI. For example, a quick test deployment can be done with Hello World CSAR as:
heat-translator --template-file=csar_hello_world.zip –deploy –stack-name=helloworld
That’s it. I sincerely hope that by now you have a better understanding of how to package application workloads in a TOSCA CSAR and deploy them into an OpenStack cloud. A special thanks to some very talented folks that I have been fortunate to work with – Ton Ngo and Vahid Hashemian of the TOSCA development team, and Matt Rutkowski, Thomas Spatzier, Derek Palma, Chris Lauwers and Luc Boutier of TOSCA TC – without whom the work I mentioned in this post couldn’t have been made possible.
In the next post, I will be talking about an important feature of TOSCA called substitution mappings. Stay tuned!
The post Package Cloud Workloads with TOSCA Cloud Service Archive appeared first on IBM OpenTech.
Powered by WPeMatico